
Feed aggregator
Announcing Zstandard in Rust
Article URL: https://trifectatech.org/blog/announcing-zstandard-in-rust/
Comments URL: https://news.ycombinator.com/item?id=48356381
Points: 1
# Comments: 0
How HN: Easy ChartFlow, Free 2D and 3D chart maker inside Chrome side panel
Article URL: https://chromewebstore.google.com/detail/easy-chartflow/jfcbhlkbkacaeihjlidngmpeehgllpog
Comments URL: https://news.ycombinator.com/item?id=48356366
Points: 1
# Comments: 1
Daily pill daraxonrasib doubles survival time for pancreatic cancer patients
Article URL: https://www.bbc.com/news/articles/cy82l435171o
Comments URL: https://news.ycombinator.com/item?id=48356342
Points: 1
# Comments: 0
Bernie Sanders: The Public Should Own Half of the Big A.I. Companies
Article URL: https://www.nytimes.com/2026/06/01/opinion/artificial-intelligence-bernie-sanders.html
Comments URL: https://news.ycombinator.com/item?id=48356341
Points: 1
# Comments: 0
Autonomous capabilities audit of a hotel voice AI assistant
Article URL: https://ktoyame.substack.com/p/autonomous-security-audit-of-a-hotel
Comments URL: https://news.ycombinator.com/item?id=48356319
Points: 2
# Comments: 0
Memgraph on Arm
Article URL: https://learn.arm.com/install-guides/memgraph-on-arm
Comments URL: https://news.ycombinator.com/item?id=48356316
Points: 2
# Comments: 0
Launch HN: Expanse (YC P26) – Unlock Wasted GPU Capacity
Hey HN, we’re Ismaeel, Eren, Yafet and Nikodem. We built Expanse (https://expanse.sh/) to increase the effective capacity of your HPC/GPU clusters running schedulers/orchestrators like Kubernetes and SLURM. We read the source code, job submission script, and the hardware a workload is about to run on to predict what the job actually needs before the cluster sees it. We also flag failures we think are about to happen and surface line-level optimisations the researcher can apply themselves.
The problem: Datacenters run at roughly 30% to 40% effective utilisation. Users request more resources than what they actually need, because of asymmetric risk: while over-requesting is bad because it’s expensive and wastes capacity that someone else could have used, under-requesting kills your job mid-run and you lose days of work. So everyone over-requests by two to three times.
We measured one national-scale HPC cluster for a month and from 122k jobs, 59% of the compute was wasted. At on-demand cloud rates for the same hardware, that’s roughly $8.5M of compute wasted in one month on one cluster. The pattern is similar in large scale compute industries as well, such as quant funds, AI labs, and manufacturing.
The four of us ran HPC and GPU training workloads at the largest quant funds and HPC facilities. Ismaeel did research at EPCC (Edinburgh’s Parallel Computing Centre, the UK’s national HPC site) under Adrian Jackson, where he built the first multimodal HPC resource predictor: a model that ingests job source code, submission scripts, hardware telemetry and cluster metadata in order to figure out how much compute will actually be needed. On a dataset of real workloads on EPCC’s own clusters it scored 34% better than any other baseline, and outperformed frontier general-purpose LLMs prompted on the same prediction task by roughly 8x. These results convinced us the problem was solvable with software.
Expanse installs on every node and hooks into SLURM (or the K8s scheduler). It ingests live hardware telemetry (DCGM, CUPTI, Cgroups, Network/IO monitoring) of your cluster creating a custom embedding of how your hardware performs. We scan any workloads about to be submitted through SLURM/K8s (plugging into the life cycles of the job so you don't have to change how you submit things) and we feed this into our deep learning models to give researchers accurate resource recommendations, failure detections, and optimisation suggestions at submission time. We fine tune cluster-specific models that get sharper over time as you run more workloads. Our models are trained to over-provision rather than under-provision due to the asymmetric outcomes of a job crashing. We also provide uncertainty estimates and p90 values to allow users to choose their risk tolerance.
We surface three capabilities to users of the cluster:
(1) Resource prediction at submit time. We predict the GPU VRAM, Utilisation, memory, CPUs and walltime the job actually needs, with a confidence interval. From these predictions we also surface failure predictions for OOMs and other memory related issues, and code line level optimisations to increase the utilisation of the job on the hardware.
(2) Live Observability. While the job runs we showcase the telemetry we are collecting through a dashboard that gives an intuitive view of what's going on in the hardware and where your workload is at in terms of code stack profiling. We dynamically profile workloads to achieve a low single digit overhead while being informative.
(3) Failure diagnosis. If a workload fails, we take all the data we collected and perform correlations on the stack profiling and the hardware telemetry we collect to surface solution oriented logs. These are one, two line logs telling you not only what happened when the job failed, but why and how to fix it with code line level suggestions.
What’s different about our approach: The state of the art for most clusters is to either have per-user historical averages from sacct (SLURM accounting DB); hand-written rules/heuristics; or frontier LLM coding agents. For per-user historical averages from sacct, once a new type of workload is submitted onto the cluster or code level changes are made the model becomes wildly inaccurate. For the LLM baseline we provided them with the submission script and source code of the workload being ran, and gave it the full capabilities of its coding harness in the cluster and it performed quite poorly. We benchmarked Expanse against the state of the art at the time (Gemini 3.5 pro, Claude Opus 4.8, GPT 5.5, Codex 5.3) and outperformed them by 8x.
You might be thinking, as these models scale and get better, they could beat us on this task; however we saw no correlation in model size or iteration on accuracy improvement. Claude Haiku actually performed better than Opus on a lot of workloads and previous iterations of models had the same, if not slightly better, accuracy. Even coding specific models, such as Codex 5.3 performed poorly (matching accuracy with GPT5.5). These models reason in a vacuum, without native support for modal inputs such as source code (to understand the underlying data flow and computational patterns), and hardware telemetry and topology (to understand performance patterns of the cluster) they cannot accurately predict the resources a workload needs. Additionally, Expanse continuously updates its internal models to make sure our predictions get more accurate as more workloads run on your cluster, making it well suited for changes in new hardware or workload patterns. LLMs are very good at writing code and hyper parameter sweeps, but they need Expanse to complete the full agentic loop for auto research. It's super easy to plug our tools into these agents, we have made our CLI tools LLM friendly. For more details on our LLM eval, check out: https://x.com/ismaeel_bashir_/status/2059683849404383283
We’re currently onboarding customers as paid pilots. Pricing is determined per-cluster. We offer a two-week measurement window where we install, ingest, and report recoverable capacity to datacenter operators, followed by a paid pilot deployment in one department at a fixed monthly fee, renewing at the same rate unless the scope expands.
If you run a HPC/GPU cluster (SLURM or K8s, 100+ GPUs), we'd love to have a talk. We’ll install on a section of your cluster for a week, send a written report of what’s recoverable, and you decide whether to keep going. If you’ve tried something like this and it didn’t work, we’d really like to hear why. And if there’s a failure mode you’d want predicted that the post doesn’t mention, drop it in this thread and we’ll write back with whether the model already catches it or what it would take to add. I never thought I’d be on the other side of launch HN :). Even if you don’t run a cluster, we’d still love to hear from you. Any thoughts on our approach, your experiences running workloads on clusters, or even anywhere you think we’re wrong - we'd love to hear it.
Tally Ho!
Comments URL: https://news.ycombinator.com/item?id=48356312
Points: 2
# Comments: 0
Show HN: Built a browser game inspired by Rust
Wanted to see how far I could get with Opus 4.8 and was impressed. Got tripped up in a few places with AI game behavior, but eventually got it to a good spot.
Comments URL: https://news.ycombinator.com/item?id=48356261
Points: 1
# Comments: 0
The Top 6 Rowing Machine Mistakes You’re Making During Your Cardio Workout
Generating OG Images in Elixir
Article URL: https://jola.dev/posts/generating-og-images
Comments URL: https://news.ycombinator.com/item?id=48356256
Points: 3
# Comments: 0
Dragos Acquires xIoT Security Firm Phosphorus
Dragos said customers will soon gain expanded asset visibility and integrated device intelligence, with automated remediation workflows and a unified platform experience to follow.
The post Dragos Acquires xIoT Security Firm Phosphorus appeared first on SecurityWeek.
NVIDIA Unveils New ARM-Based AI/Graphics Superchip Coming to Windows PCs and Laptops
At the 2026 Retail Technology Show, retailers share some of the challenges and benefits of implementing emerging technologies
Pluto – An x86 (Ring 0, Protected Mode) kernel written in Zig
Article URL: https://github.com/ZystemOS/pluto
Comments URL: https://news.ycombinator.com/item?id=48355824
Points: 1
# Comments: 0
A compressed-spring model of spiral galaxy formation (initial email version)
Article URL: https://theeggandtherock.com/p/a-compressed-spring-model-of-spiral
Comments URL: https://news.ycombinator.com/item?id=48355809
Points: 1
# Comments: 0
Work from Home and Disability Employment
Article URL: https://www.aeaweb.org/articles?id=10.1257/aeri.20240538
Comments URL: https://news.ycombinator.com/item?id=48355800
Points: 1
# Comments: 0
Linux 7.2 Proceeding to Deprecate Af_alg Due to "Massive Attack Surface"
Article URL: https://www.phoronix.com/news/Linux-AF-ALG-Deprecation
Comments URL: https://news.ycombinator.com/item?id=48355766
Points: 2
# Comments: 0
When AI Crosses the Line: The Matplotlib Incident
Article URL: https://members.sigmazero.cc/posts/when-ai-crosses-159174096?postId=when-ai-crosses-159174096
Comments URL: https://news.ycombinator.com/item?id=48355751
Points: 3
# Comments: 0
MiniMax M3 Benchmarks One Pager
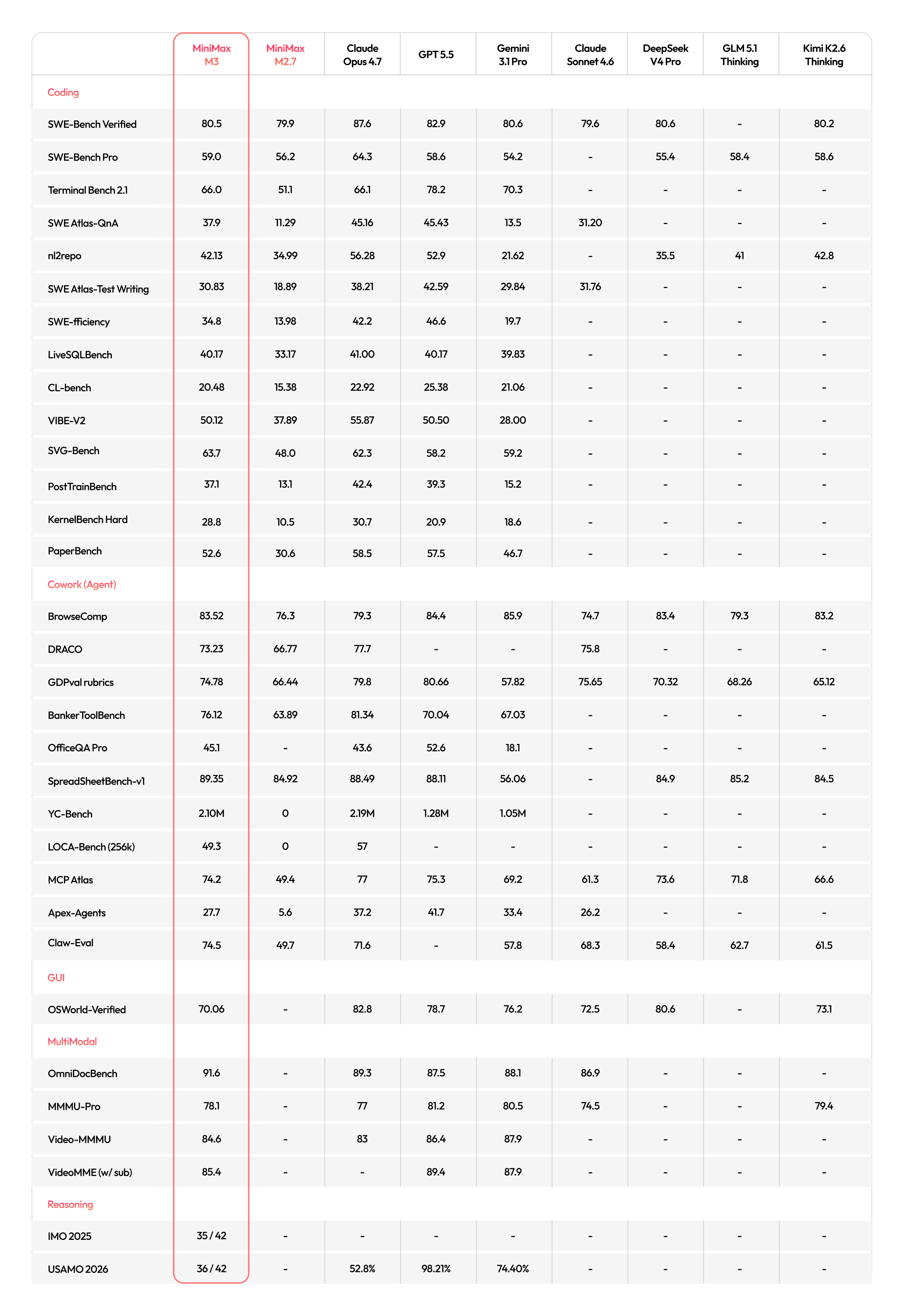{kind=link}
Article URL: https://filecdn.minimax.chat/public/img_v3_02128_b7726cd8-879a-4b7a-a9da-db4395ea597g-1780272508686.jpg
Comments URL: https://news.ycombinator.com/item?id=48355745
Points: 1
# Comments: 1